

31·
1 day agoIf a publisher doesn’t want modders improving the value of their product, I don’t feel too inclined to argue with them. There are no shortage of other games from more-amenable-to-modding publishers that could benefit from mods.
If a publisher doesn’t want modders improving the value of their product, I don’t feel too inclined to argue with them. There are no shortage of other games from more-amenable-to-modding publishers that could benefit from mods.
Could be distributing a modified copy of a copyrighted binary.
11,000 meters
6,000 meters
5,000 meters
I’m not entirely sure of the application here.
https://en.wikipedia.org/wiki/Deep_diving
The deepest dive listed here is:
534 m (1,752 ft): COMEX Hydra 8 dives on hydreliox (February 1988 offshore Marseille, France).[2][4][10]
I guess you could build a submersible and put the watch on an arm outside the submersible or something.
I don’t think that we’re going to throw a little more hardware an one and it’s going to suddenly become an AGI, but that doesn’t mean that it doesn’t have considerable utility.
Also, there are a bunch of “composite” systems that have been built in AI research that use multiple mechanisms. Even if you’re off trying to do human-level AI, you may use components in that system that are not themselves fully-capable of acting in such a way.
Like, okay. Think of our own minds. We’ve got a bunch of hard-coded vision stuff, which is part of why we can get weird optical illusions. Our visual processing system isn’t an intelligence on its own, but it’s an important part of letting us function as humans in the world.
Broadly-speaking, I think that mixing microphones or cameras with remotely-connected devices is also kind of asking for trouble.
Windows 95 will now run Solitaire to calm you.
If it wanted to calm me, it’d ship with Eight Off. Freecell frustrates me.
So, I think that there are at least two issues raised here.
First, that CVSS scores may not do a great job of capturing the severity of a bug, and that this may cause the end-user or their insurer to mis-assess the severity of the bug in terms of how they handle the issue on the system.
I am not too worried about this, because what matters here is how relatively good what they’re doing is. It doesn’t need to be perfect, just the best of the alternatives, and the alternative is probably having no information. The goal is not to perfectly-harden all systems, but a best effort to help IT allocate resources. An end-user for whom this is insufficient could always do their own, per-user per-vulnerability assessment, but frankly, I’d guess that for almost all users, if they had to do that, they probably wouldn’t. An insurer can take into account an error rate on a security scoring tool – they are in the business of assessing and dealing with uncertainties. Insurers work with all kinds of data, some of which is only vaguely-correlated with the actual risk.
In the curl security team we have discussed setting “fixed” (fake) scores on our CVE entries just in order to prevent CISA or anyone else to ruin them, but we have decided not to since that would be close to lying about them and we actually work fiercely to make sure we have everything correct and meticulously described.
Every user or distributor of the project should set scores for their different use cases. Maybe even different ones for different cases. Then it could perhaps work.
The thing is that for the vast bulk of users, that per-user assessment is not going to happen. So the alternative is that their scanner has no severity information. I doubt that there’s anything specific to curl that forces that one number to be less-accurate then for other software packages. I don’t think that other projects that do use this expect it to be perfect, but surely it’s possible to beat no information. If an organization is worried enough about the accuracy of such a score, they can always do a full review of all identified vulnerabilities – if you’re the NSA or whoever, have the capability and need, then you probably also don’t need to worry about being mislead by the score. Hence:
The reality is that users seem to want the scores so bad that CISA will add CVSS nonetheless, mandatory or not.
I mean, that’s because most of them are not going to reasonably going to be able to review and understand every vulnerability themselves and it’s implications for them. They want some kind of guidance as to how to prioritize their resources.
If the author is concerned philosophically about the limitations of the system to the point that they feel that it damages their credibility to provide such a score, I’d think maybe put up an advisory that the CVSS score is only an approximation, and could be misleading for some users’ specific use cases.
If someone wanted to come up with a more-sophisticated system – like, say, a multiple score system, something that has a “minimum impact” and “maximum impact” severity score per vulnerability, or something that has a score for several scenarios (local attacker able to invoke software, remote attacker, attacker on same system but different user), maybe something like that could work, but I don’t think that that’s what the author is arguing for – he’s arguing that each end-user do an impact assessment to get a score tailored to them.
Second, that an excessive CVSS score assigned by someone else may result in the curl team getting hassled by worried end users and spending time on it. I think that the best approach is just to mechanically assign something approximate off the curl severity assessment. But even if you don’t – I mean, if you’re hassling an open-source project in the first place about a known, open vulnerability, I think that the right response is to say “submit a patch or wait until it gets fixed”. Like, even if the bug actually were serious, it’s not like going to to the dev team for support is going to accomplish anything. They will already know about the vulnerability and will have prioritized their resources.
Finally, looking at the bug bounty page referenced in the article, it seems like the bug bounty currently uses a CVSS score to award a bounty. If curl doesn’t assign CVSS scores, I’m a little puzzled as to how this works. Maybe they only go to vulnerabilities from the bug bounty program?
https://curl.se/docs/bugbounty.html
The grading of each reported vulnerability that makes a reward claim is performed by the curl security team. The grading is based on the CVSS (Common Vulnerability Scoring System) 3.0.
No, but if your concern is just that you personally want control over the model and you don’t have to be able to operate it without an Internet connection and don’t need high bandwidth to the thing being run, I would at least give consideration to sticking a regular GPU into a desktop that you control and using it remotely from your laptop. This is what I’ve done.
I just linked to a new eGPU above. I noticed that it was the “RTX 5090 Laptop GPU”. Note that the (desktop) RTX 5090 and the RTX 5090 Laptop are not the same hardware; the former is a lot more power-hungry and performs better. It may be that a desktop GPU is available as an eGPU, but I’d be aware that there is a difference and you may not be getting what you are expecting.
At least the software that I’ve used is specifically designed to be used remotely – like, you typically fire up a web browser and then talk to Automatic1111 or ComfyUI or KoboldAI or whatever. I’ve had no problems with that.
This is power-hungry. Even if you can carry the hardware with you, using it without a power outlet handy is probably going to be a little annoying.
It’s probably going to have fans spun up on reasonable hardware. I’d just as soon have the fan noise and heat not right next to me.
While the desktop probably costs something, so does the eGPU.
At least some software – depends upon what you want to do – does a pretty good job of queuing up tasks and churning on it, which means that you can, remotely, just look at your output and then fire up more work and then put your laptop to sleep or whatever. That’s not very useful if you want to run an interactive LLM-based chatbot or something, but ComfyUI can queue up a bunch of image-generation jobs with different prompts or something.
Now, all that being said, that does have some drawbacks.
It means a desktop, if you don’t already have one (though really all it needs is that beefy GPU).
It means that your laptop has to have some form of Internet connectivity. I can comfortably use it on a tethered cell phone for what I do, but it’s something to keep in mind.
I am sure that there is probably some sort of software out there where you really want the GPU to be local to where you are.
You can’t also use your beefy GPU for 3D games on your laptop, if that’s something that you want to do. I imagine that for some people, this is a major point.
You need some way to reach the desktop remotely over the Internet.
This is not to ding eGPUs – they’re a good option for certain use cases – but just to encourage people to at least consider the “use desktop with desktop GPU remotely” approach if their main interest is in running AI stuff.
I think power requirements of the last years of GPUs have also made them less practical
Wait, what? If power requirements are going up, then I’d say that there’s more pressure for an eGPU, if anything. Laptops are limited in heat dissipation compared to desktops.
I can understand someone saying “you’re better off using a desktop for gaming with powerful GPUs, if you can deal with not moving it around”. But I wouldn’t expect that power-hungry GPUs would make internal GPUs in laptops more desirable.
eGPUs have all but disappeared. 90% of the models available in 2019 are no longer available with no models to replace them.
kagis
This is the first hit I get for “2025 egpu”
The 2025 ROG XG Mobile Leads New Era of eGPUs with Thunderbolt 5
I think that there are still new ones coming out.
Probably, as I imagine that if it can display a configurable prompt, it can send whatever escape sequences it wants. Like, I expect that one could set it to show the prompt with whatever colors one wants. But it won’t govern what software does to the terminal subsequent to handing off control to that software.
My system uses agetty. From its man page:
The issue files may contain certain escape codes to display the system name, date, time et cetera. All escape codes consist of a backslash (\) immediately followed by one of the characters listed below.
e or e{name} Translate the human-readable name to an escape sequence and insert it (for example: \e{red}Alert text.\e{reset}). If the name argument is not specified, then insert \033. The currently supported names are: black, blink, blue, bold, brown, cyan, darkgray, gray, green, halfbright, lightblue, lightcyan, lightgray, lightgreen, lightmagenta, lightred, magenta, red, reset, reverse, yellow and white. All unknown names are silently ignored.
So if you insert the relevant escape sequences into /etc/issue, you can have the login prompt screen be whatever set of colors you want.
I don’t have agetty do that, but I do use emptty on tty7. emptty is a console-based display manager – that is, I log in on a console and then start Sway from that. On Debian, emptty defaults to showing a color prompt (I mean, it’s a light-on-dark prompt by default, but I’m sure that one could set it up to do whatever).
EDIT: /etc/emptty/motd
I see wall (Unix) but not talk (Unix) or PHONE (VMS).
I’m not sure what you mean by “tty”.
Televisions or computer displays? They didn’t (well, normally, probably some television out there that can do it) – if you plug an Apple II into a television or a display, it’s just gonna be light-on-dark.
Hardware dumb terminals, like VT100s? I’ve never seen one configured that way, but it might be possible that some supported running in light-on-dark mode. There are escape codes that will throw the terminal into showing reverse mode, and that was used for stuff like highlighting text, but I don’t know if there was an option invisible to the remote end to reverse colors. Like, you could set some of the default terminal modes at boot, stuff like terminal speed and such, but I don’t know if there’s a persistent flag that would always override what the remote end was using.
kagis
https://vt100.net/docs/vt510-rm/DECSCNM.html
Screen Mode: Light or Dark Screen
This control function selects a dark or light background on the screen.
Default: Dark background.
https://vt100.net/docs/vt100-ug/chapter3.html
Screen:
Changeable from Host Computer? Yes (DECSCNM)
Saved in NVR and Changeable in SET-UP: Yes
So on the VT100, there was a flag you could set that would be saved in nonvolatile memory that would persist across terminal boots, but it also could be flipped by the remote end, wasn’t invisible to it. If you used escape sequences that fiddled with the color mode, I’m not sure if it’d retain that.
Virtual terminal programs? xterm has -rv/+rv, which flips the foreground/background color, and pretty much all virtual terminal programs have some way to configure the 8/16 ANSI colors they use. If you’re talking changing how they interpret 8-bit color codes or 24-bit color codes, I don’t believe that I’ve typically seen some sort of mapping system in virtual terminal software – like, normally one configures software emitting those color codes on a per-program basis; normally, software that uses one of those will also have configurable color options. Like, Cataclysm: Dark Days Ahead, which uses IIRC 8-bit color, has a default set of colors, a set of alternate themes, and can be configured on a per-color basis. Ditto for emacs. Most console software uses the ANSI colormap, so remapping that in virtual terminal software handles most cases. Use of either 8-bit or 24-bit color by console software is fairly rare, so that’s tolerable today, though I imagine that if use becomes really common, that maybe virtual terminal software will try to add some sort of high-level mapping of colors.
It was due to neccesity too that light on dark was used in CLI environments, due to the way CRT work, not because it’s superior or whatever.
No, you can run dark-on-light material on CRTs just fine. Literally all of the screenshots I have in the above post with dark-on-light are of computer systems that were sold with CRTs. The transition to LCDs didn’t come until something like twenty years after the transition from light-on-dark.
That was Nissan. I don’t think that it was ever established that they were, just that their click-through privacy agreement had the consumer explicitly give them the right to do so.
kagis
They apparently say that they put it in there because the data that they did collect would permit inferring sexual orientation (like, I assume that if they’re harvesting location data and someone is parking outside gay bars, it’s probably possible to data-mine that).
https://nypost.com/2023/09/06/nissan-kia-collect-data-about-drivers-sexual-activity/
On Nissan’s official web page outlining its privacy policy, the Japan-based company said that it collects drivers’ “sensitive personal information, including driver’s license number, national or state identification number, citizenship status, immigration status, race, national origin, religious or philosophical beliefs, sexual orientation, sexual activity, precise geolocation, health diagnosis data, and genetic information.”
“Nissan does not knowingly collect or disclose consumer information on sexual activity or sexual orientation,” a company spokesperson told The Post.
“Some state laws require us to account for inadvertent data collection or information that could be inferred from other data, such as geolocation.”
A massive battery fire in California could cast a dark shadow on clean energy expansion
Fire may be a risk for grid-scale battery storage, but I’m not sold that it’s a fundamental one.
The article points out that this isn’t intrinsically tied to battery storage – one can store the batteries outdoors so that heat gets vented instead of trapped in a building if one battery catches fire, and that the reason that these were indoors is because the facility was one repurposed from non-battery-storage.
But even aside from that, the energy industry works with a lot of very flammable materials all the time – natural gas, oil, coal, flammable fluids in large transformers. While there’s the occasional fire, when one happens, we don’t normally conclude that the broader electricity industry isn’t workable due to fire risk.
Apparently they capitalize it, so the article author kinda screwed it up:
https://en.wikipedia.org/wiki/Starlink_(disambiguation)
STARLINK, a brand of automotive connectivity systems by Subaru
Shah and Curry’s research that led them to the discovery of Subaru’s vulnerabilities began when they found that Curry’s mother’s Starlink app connected to the domain SubaruCS.com, which they realized was an administrative domain for employees. Scouring that site for security flaws, they found that they could reset employees’ passwords simply by guessing their email address, which gave them the ability to take over any employee’s account whose email they could find. The password reset functionality did ask for answers to two security questions, but they found that those answers were checked with code that ran locally in a user’s browser, not on Subaru’s server, allowing the safeguard to be easily bypassed. “There were really multiple systemic failures that led to this,” Shah says.
Yeah, this kinda bothers me with computer security in general. So, the above is really poor design, right? But that emerges from the following:
Writing secure code is hard. Writing bug-free code in general is hard, haven’t even solved that one yet, but specifically for security bugs you have someone down the line potentially actively trying to exploit the code.
It’s often not very immediately visible to anyone how actually secure code code is. Not to customers, not to people at the company using the code, and sometimes not even to the code’s author. It’s not even very easy to quantify security – I mean, there are attempts to do things like security certification of products, but…they’re all kind of limited.
Cost – and thus limitations on time expended and the knowledge base of whoever you have working on the thing – is always going to be present. That’s very much going to be visible to the company. Insecure code is cheaper to write than secure code.
In general, if you can’t evaluate something, it’s probably not going to be very good, because it won’t be taken into account in purchasing decisions. If a consumer buys a car, they can realistically evaluate its 0-60 time or the trunk space it has. But they cannot realistically evaluate how secure the protection of their data is. And it’s kinda hard to evaluate how secure code is. Even if you look at a history of exploits (software package X has had more reported security issues than software package Y), different code gets different levels of scrutiny.
You can disincentivize it via market regulation with fines. But that’s got its own set of issues, like encouraging companies not to report actual problems, where they can get away with it. And it’s not totally clear to me that companies are really able to effectively evaluate the security of the code they have.
And I’ve not been getting more comfortable with this over time, as compromises have gotten worse and worse.
thinks
Maybe do something like we have with whistleblower rewards.
https://www.whistleblowers.org/whistleblower-protections-and-rewards/
- The False Claims Act, which requires payment to whistleblowers of between 15 and 30 percent of the government’s monetary sanctions collected if they assist with prosecution of fraud in connection with government contracting and other government programs;
- The Dodd-Frank Act, which requires payment to whistleblowers of between 10 percent and 30 percent of monetary sanctions collected if they assist with prosecution of securities and commodities fraud; and
- The IRS whistleblower law, which requires payment to whistleblowers of 15 to 30 percent of monetary sanctions collected if they assist with prosecution of tax fraud.
So, okay. Say we set something up where fines for having security flaws exposing certain data or providing access to certain controls exist, and white hat hackers get a mandatory N percent of that fine if they report it to the appropriate government agency. That creates an incentive to have an unaffiliated third party looking for problems. That’s a more-antagonistic relationship with the target than normally currently exists – today, we just expect white hats to report bugs for reputation or maybe, for companies that have it, for a reporting reward. This shifts things so that you have a bunch of people effectively working for the government. But it’s also a market-based approach – the government’s just setting incentives.
Because otherwise, you have the incentives set for the company involved not to care all that much, and the hackers out there to go do black hat stuff, things like ransomware and espionage.
I’d imagine that it’d also be possible for an insurance market for covering fines of this sort to show up and for them to develop and mandate their own best practices for customers.
The status quo for computer security is just horrendous, and as more data is logged and computers become increasingly present everywhere, the issue is only going to get worse. If not this, then something else really does need to change.
SDL is a widely-used-on-Linux platform abstraction layer. A lot of games have targeted it to make themselves more portable and provide some basic functionality.
If you’ve been on Linux for some years, you’ve probably run into it. I’d guess that most Windows users probably wouldn’t know what it is, though.
Not to mention that the article author apparently likes dark-on-light coloration (“light mode”), whereas I like light-on-dark (“dark mode”).
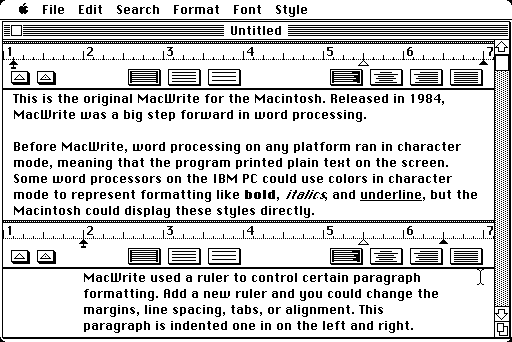
Traditionally, most computers were light-on-dark. I think it was the Mac that really shifted things to dark-on-light:
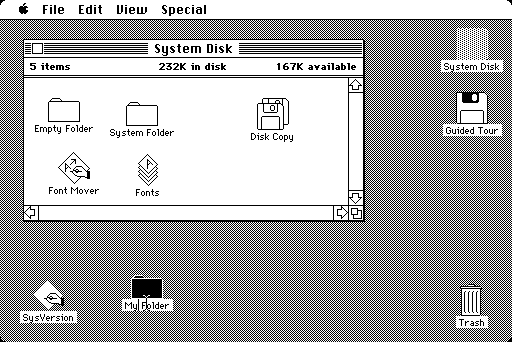
My understanding from past reading was that that change was made because of the observation that at the time, people were generally working with computer representations of paper documents. For ink economy reasons, paper documents were normally dark-on-light. Ink costs something, so normally you’d rather put ink on 5% of the page rather than 95% of the page. If you had a computer showing a light-on-dark image of a document that would be subsequently printed and be dark-on-light on paper, that’d really break the WYSIWYG paradigm emerging at the time. So word processors and the like drove that decision to move to dark-on-light:
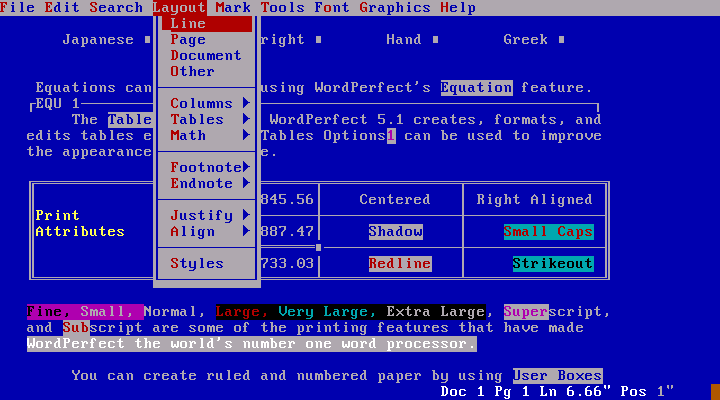
Prior to that, a word processor might have looked something like this (WordPerfect for DOS):
Technically, I suppose it wasn’t the Mac where that “dark-on-light-following-paper” convention originated, just where it was popularized. The Apple IIgs had some kind of optional graphical environment that looked like a proto-Mac environment, though I rarely saw it used:
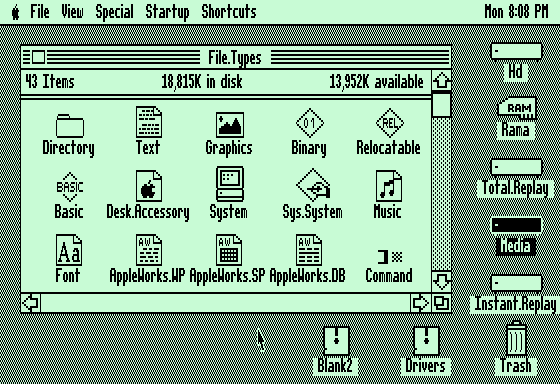
Update: apparently that wasn’t actually released until after the Mac. This says that that graphical desktop was released in 1985, while the original 128K Mac came out in 1984. So it’s really a dead-end side branch offshoot, rather than a predecessor.
The Mac derived from the Lisa at Apple (which never became very widespread):
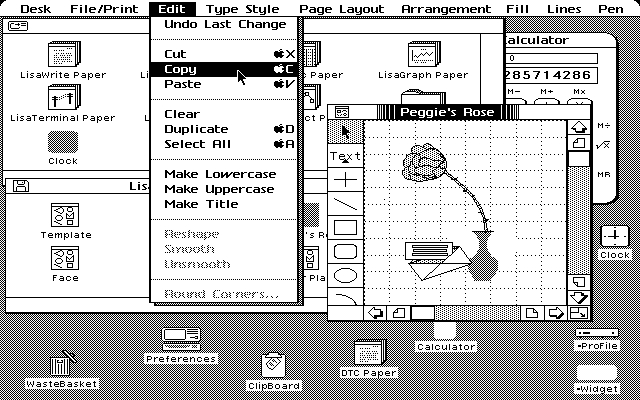
And that derived from the Xerox Alto:

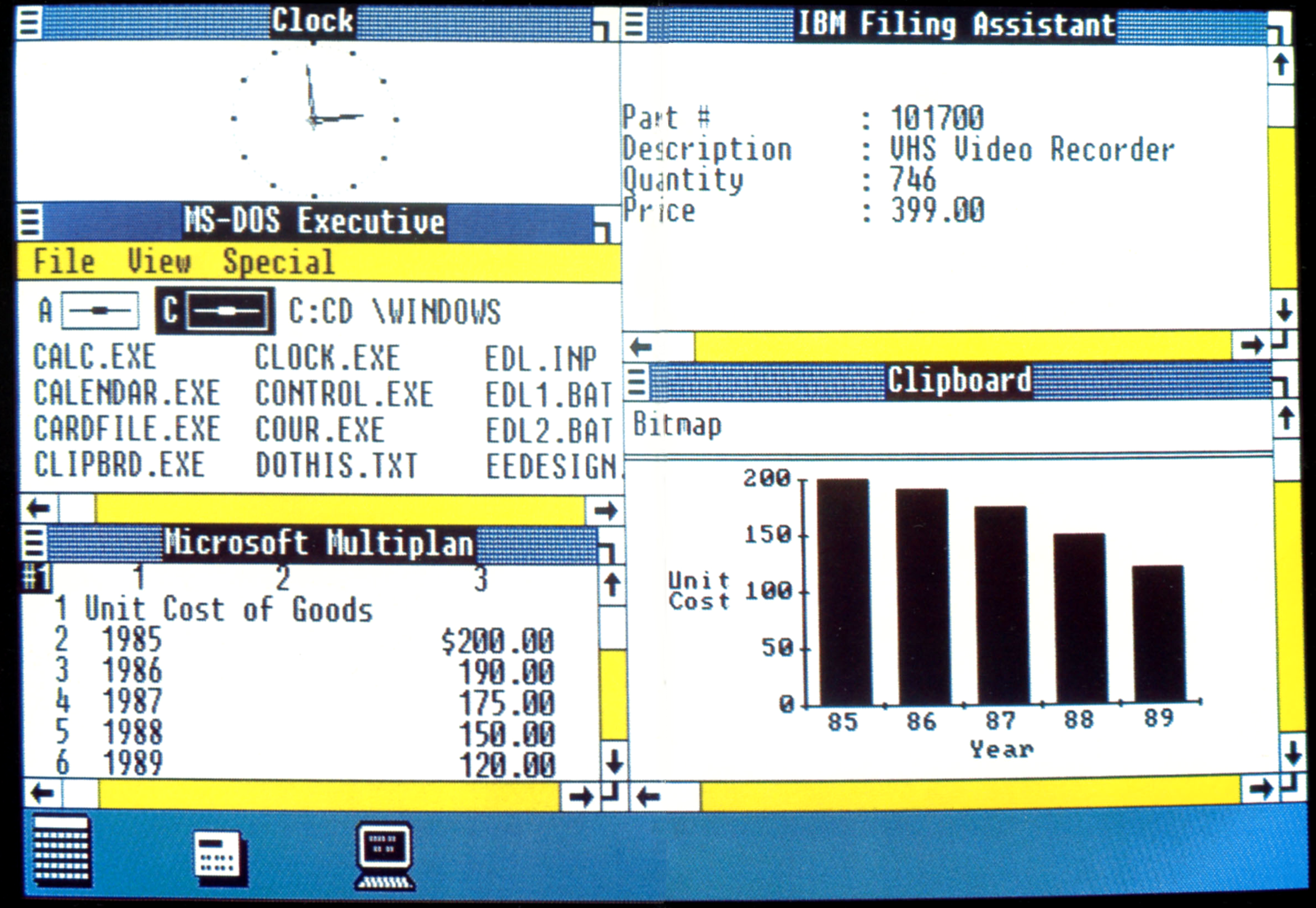
But for practical purposes, I think that it’s reasonably fair to say that the Mac was really what spread dark-on-light. Then Windows picked up the convention, and it was really firmly entrenched:
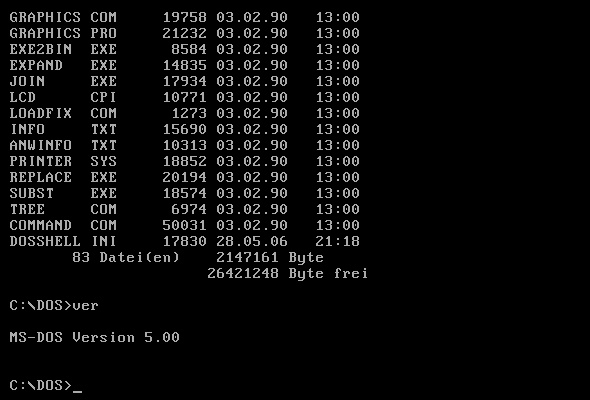
Prior to that, MS-DOS was normally light-on-dark (with the basic command line environment being white-on-black, though with some apps following a convention of light on blue):
Apple ProDOS, widely used on Apple computers prior to the Mac, was light-on-dark:
The same was true of other early text-based PC environments, like the Commodore 64:

Or the TRS-80:
When I used VAX/VMS, it was normally off a VT terminal that would have been light-on-dark, normally green, amber, or white on black, depending upon the terminal:

And as far as I can recall, terminals for Unix were light-on-dark.
If you go all the way back before video terminals to teleprinters, those were putting their output directly on paper, so the ink issue comes up again, and they were dark-on-light:

But I think that there’s a pretty good argument that, absent ink economy constraints, the historical preference has been to use light-on-dark on video displays.
There’s also some argument that for OLED displays – and, one assumes, any future emissive displays, where you only light up what needs to be light, rather than the LCD approach of lighting the whole thing up and then blocking and converting to heat what you don’t want to be light – draw somewhat less power for light-on-dark. That provides some battery benefits on portable devices, though in most cases, that’s probably not a huge issue compared to eye comfort.
When I go to the NTSB’s media relations page, there is one reference to the NTSB Twitter account. It is listed as the way to get the latest updates on investigations. No email mailing list is provided:
https://www.ntsb.gov/news/Pages/media_resources.aspx
I get this:
The thing is, looking at the Wayback Machine, that text seems to have also been the same pre-Trump:
https://web.archive.org/web/20250104091444/https://www.ntsb.gov/news/Pages/media_resources.aspx
It’s not entirely clear to me, even after rereading the submitted article’s text, what the policy change was. The article seems to imply that there was some sort of mailing list prior to this point – unless they’re only referencing contacting a human at the listed email address – but if that was the case, I don’t see it listed. And if they’re only talking about contacting a human at the email address, I’m not sure what has changed – it seems to have been and still be present, but with the NTSB asking media to use it as a secondary method.
EDIT: Correction. There are four references, but all of them appear to be identical pre- and post-Trump:
EDIT2: So, in summary, I don’t think that they’re changing how they communicate. I think that they’re just saying that they aren’t taking direct questions on a per-reporter basis on this (high-profile) incident, but just putting out the same static material to everyone.
That being said, if I were a reporter, I kind of would like to have a mailing list. I understand that in the past, spoofing press releases (even pre-email; fax was a target) was a tactic used against media, so you’d probably want to have X.509 or PGP signing for emails to the list.